Bedienung > Hauptmenü > Menü: Einstellungen > Projekteinstellungen > xerces DOM
In der oberen Hälfte der Dialogseite befinden sich die Optionen, die für ein alleinstehendes ("standalone") XML-Dokument gesetzt sein müssen. Ein derartiges Dokument hängt nicht von einer DTD ab.
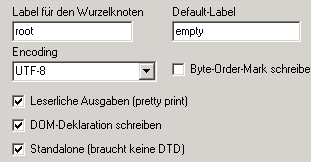
Die angezeigten Optionen produzieren ein Dokument, das aussieht wie folgt:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
<root>
...
</root>
Label für den Wurzelknoten
Hier wird das tag definiert, dass die Wurzel des XML-Dokuments ausmacht. Im Beispiel wird es "root" genannt.
Default-Label
Jedes tag in einem XML-Dokument muss einen Namen haben. Dieser Name ist das Label einer dnode. Um die Analogie der Konstruktionsmöglichkeiten von Bäumen aus node's und dnode's zu bewahren, ist es erlaubt dnode's ohne explizit definiertes Label zu verwenden. Solche dnode's erhalten dann intern automatisch das Default-Label zugewiesen.
dnode dn("". "text");
erscheint im XML Dokument mit obigem Default-Label als:
<empty>text</empty>
Vor dem Aufruf des Parsers im generierten C++-Code, muss das Default-Label manuell gesetzt werden. Die CTT_DomNode Klasse hat hierfür eine statische Methode;
dnode::SetDefaultLabel(L"default_label");
Kodierung:
Xerces unterstützt zur Ausgabe der XML-Dokumente viele Kodierungen, die gleich diskutiert werden. In der Arbeitsoberfläche des TextTransformer wird aber nur der ANSI-Zeichensatz (Windows-1252) korrekt dargestellt. In der Entwicklungsphase eines Projekts sollte daher möglichst mit ANSI oder einer anderen 8-Bit Kodierung gearbeitet werden. Andernfalls erscheint die Meldung im Ausgabefenster:
Kodierung kann nicht in das Ausgabefenster der IDE geschrieben werden
Wenn eine Projekt über den Transformations-Manager, das Kommandozeilen-Werkzeug oder die Delphi-Komponenten ausgeführt wird, besteht keine Einschränkung für die Kodierung.
Einige der folgenden Bemerkungen zu den Kodierungen stammen von
http://xerces.apache.org/xerces-c/faq-parse.html
ISO-8859-1 (aka Latin1)
Auf UNIX Systemen in Ländern, in denen westeuropäische Sprachen gesprochen werden, wird normalerweise ISO-8859-1 verwendet.
Windows-1252
Der Default-Zeichensatz auf Windows Systemen ist Windows-1252 (ANSI), und nicht ISO-8859-1. Während Xerces-C++ diese Windows Kodierung verarbeitet, ist die Wahrscheinlichkeit für die Portabilität der XML-Daten gering, da es von anderen XML-Verarbeitungswerkzeugen wenig unterstützt wird.
UTF-8
UTF-8 - wie UTF-16 - deckt den vollen Unicode-Zeichensatz ab, der alle wichtigen nationalen und internationalen Zeichen sowie Industrie-Zeichensätze umfasst. Diese Kodierung - ebenso wie UTF-16 - ist durch XML-Prozessoren besser unterstützt als alle übrigen Kodierungen.
Effizientes. utf-8 hat geringe Speicheranforderungen für Dokumente, die hauptsächlich aus Zeichen des lateinischen Alphabets bestehen.
UTF-16 (Big/Small Endian)
UTF-16 - wie UTF-8 - deckt den vollen Unicode-Zeichensatz ab, der alle wichtigen nationalen und internationalen Zeichen sowie Industrie-Zeichensätze umfasst. Diese Kodierung - ebenso wie UTF-8 - ist durch XML-Prozessoren besser unterstützt als alle übrigen Kodierungen.
UCS4 (Big/Small Endian)
EBCDIC code pages IBM037, IBM1047 and IBM1140 encodings
(Extended Binary Coded Decimals Interchange Code)
IBM1140
IBM037
IBM1047
Wenn EBCDIC kodierte XML-Daten erzeugt werden, ist IBM1140 die bevorzugte Kodierung. Die IBM037-Kodierung, auch ebcdic-cp-us genannt, ist nahezu identisch mit IBM1140, aber ihm fehlt das Euro Symbol.
Byte-Order-Mark (BOM) schreiben
Bei einigen Kodierungen wird eine Byte Order Mark (BOM, dt. Bytereihenfolge-Markierung) an den Anfang einer Datei gesetzt. Die Markierung gibt an, in welcher Reihenfolge die Bytes ausgewertet werden müssen, falls einzelne Zeichen aus mehreren Bytes bestehen, wie in UTF-16.
Das BOM wird nur für folgende Kodierungen geschrieben
| • | UTF-16 |
| • | UTF-16LE |
| • | UTF-16BE |
| • | UCS-4 |
| • | UCS-4LE |
| • | UCS-4BE |
Bei UTF-8 kann eine solche Markierung optional dazu verwendet werden, die Datei als UTF-8 kodiert zu kennzeichnen. Es ist aber nicht möglich für UTF-8 die automatische Voranstellung einer BOM's einzustellen, da xerces dies nicht unterstützt. Die BOM kann aber durch folgenden Code im Programm dem Dokument vorausgeschickt werden:
out << char(0xEF) << char(0xBB) << char(0xBF);
WriteDocument();
Wird eine UTF-8 kodierte Datei als ANSI-Datei gelesen, erscheint diese Marke als Zeichenfolge: .
Kodierung |
Bytefolge |
UTF-8 |
EF BB BF |
UTF-16 Big Endian |
FE FF |
UTF-16 Little Endian |
FF FE |
Leserliche Ausgabe (pretty-print)
Durch Einfügung von Zeilenumbrüche und Leerzeichen wird das Dokument in einer vom Menschen gut lesbaren Form - pretty-print -erzeugt.
Wenn diese Option gesetzt ist und das Dokument mit WriteDocument ohne Parameter geschrieben werden soll, ist es für einige Kodierungen - z.B. für UTF-16 - erforderlich, die Option für eine binäre Ausgabe zu setzen.
DOM-Deklaration schreiben
In obigem Beispiel ist die Zeile:
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
die Deklaration des Dokuments. Soll sie ganz weggelassen werden oder im Programm explizit formuliert werden - nur für UTF-8 - , so kann die Checkbox deaktiviert werden.
Standalone
Wenn das erzeugte Dokument nicht von einer DTD abhängen soll, so sollte diesen Box aktiviert sein und umgekehrt.