Bedienung > Hauptmenü > Menü: Einstellungen > Projekteinstellungen > Parser/Scanner > Auszulassende Zeichen
Beim Zerlegen von Texten in Symbole können überflüssige Zeichen übersprungen werden. Dies kann die Formulierung der Regeln stark vereinfachen. Zeichen die für die Zerlegung des Textes bedeutungslos sind können hier in den Projektoptionen global für alle Regeln ausgewählt werden. Die auszulassenden Zeichen haben keine Auswirkungen auf die regulären Ausdrücke selbst, sondern lediglich auf die Textpostionen von denen aus nach dem nächsten Token gesucht wird.
Beispiel:
Eine Regel für die Summe zweier Terme wäre intuitiv einfach zu formulieren als:
Summe = Term "+" Term
Durch diese Regel soll aber nicht nur ein Rechenausdruck wie
"23+4"
erkannt werden sondern auch
"23 + 4" und " 23 + 4" etc.
Die Leerzeichen zwischen den Zahlen und dem Plus-Operator sind irrelevant und können übersprungen werden. Ist das Leerzeichen nicht in den Optionen als auszulassendes Zeichen eingestellt, so müssen ein zusätzliche Token für die Lücke zwischen den Termen und dem Operator definiert werden. Möglich wäre
Space = "[\n\r\t ]*" (umfasst auch Zeilenumbrüche und Tabulatoren).
Statt obiger Regel wäre zu formulieren:
Summe = Term Space "+" Space Term
Je nach dem, ob die Checkbox Regex aktiviert ist oder nicht, werden die auszulassenden Zeichen durch eine Zeichenliste oder durch einen regulären Ausdruck definiert.
auszulassenden Zeichen mittels einer Zeichenliste definieren
Leerzeichen, Zeilenumbrüche und Tabulatoren dienen in sehr vielen Texten zur Trennung der Token und können bei der Analyse übersprungen werden. Sie sind daher standardmäßig als auszulassende Zeichen eingestellt und können bequem mittels der entsprechenden Checkboxen der Liste hinzugefügt oder entfernt werden.
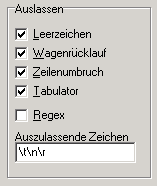
Weitere Zeichen können direkt der Liste hinzugefügt werden.
auszulassenden Zeichen mittels eines regulären Ausdrucks definieren
Statt eine Liste der auszulassenden Zeichen zu definieren, kann auch ein regulärer Ausdruck zur Bestimmung des auszulassenden Textes verwendet werden. Hierzu muss das Kästchen Regex aktiviert werden. Der Text des Editfeldes wird nun als regulärer Ausdruck interpretiert. Beispielsweise könnte hier "\s*" eingegeben werden,. Dann würden alle Zeichen der Menge \s ausgelassen werden. Das ergäbe in etwa das gleiche Resultat wie die Zeichenliste die erhalten wird, wenn sämtlichen Checkboxen markiert sind. Ein sinnvolleres Beispiel für die Verwendung eines regulären Ausdrucks an dieser Stelle wäre:
(\s|//[^\r\n]*)*
Dieser Ausdruck veranlasst nicht nur das Überspringen der Leerzeichen sondern auch von Zeilenkommentaren.
Statt eines expliziten regulären Ausdrucks kann auch der Name eines bereits definierten Tokens in das Editfeld eingegeben werden, das dann zur Bestimmung der auszulassenden Textabschnitte verwendet wird.. Bei aktivierter Regex-Checkbox wird der Text im Editfeld als Tokennamen interpretiert, wenn er nur aus Literalen besteht.
Anm: Einem regulären Ausdruck, der die auszulassenden Zeichen definiert wird automatisch nach vorheriger Klammerung der Anker "\\A" vorangestellt. Damit wird gewährleistet, dass die übersprungenen Textabschnitte stets an der aktuellen Position beginnen.
Anm.: Während es bei der Verwendung von Zeichenlisten möglich ist mit xState.str(-1) auf die ausgelassenen Zeichen zuzugreifen, die einem SKIP-Knoten folgen, ist dies bei Verwendung eines regulären Ausdrucks nicht möglich.