Der Java-Parser ist ein relativ umfangreiches Projekt und daraus ein vollständiges Transformations-Programm zu machen lässt eine Menge Arbeit erwarten. Hier können die Assistenten des TextTransformers eine große Hilfe leisten. Als Beispiel soll zunächst mit dem Baum-Assistenten der Code zur Erzeugung eines Parse-Baums in das Projekt eingefügt werden. Mit dem Funktionstabellen-Assistenten können dann Funktionen erstellt werden, mit denen der Parse-Baum ausgewertet werden kann.
Häufig ist es empfehlenswert, zunächst ein Transformations-Programm zu erstellen, dass die Quell-Dateien schlicht kopiert. Anhand eines solchen Programms lässt sich zum einen der Parser und der Parse-Baum gut testen: das Programm arbeitet korrekt, wenn die transformierten Dateien mit den Quelldateien identisch sind. Zum zweiten können an dem Kopierprogramm dann einfache Änderungen vorgenommen werden, deren Resultate ebenfalls leicht zu verifizieren sind.
Wer die folgenden Schritte nicht im einzelnen nachvollziehen möchte, kann das fertige Ergebnis des Baum-Assistenten auch direkt laden:
...\TextTransformer\Beispiele\Java\JavaTree.ttp
Wenn man den Baum-Assistenten im Hilfe-Menü aufruft, so erscheint zunächst eine Auswahlmöglichkeit für die Art und Weise, wie der Baum erzeugt werden soll. Hier wird die Voreinstellung belassen.

Als nächstes erscheint eine Auswahl für den Knotentyp und ein Eingabefeld für den Knoten-Namen. Hier wird node als Typ und "n" als Name gewählt:
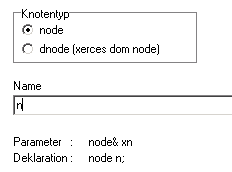
Unter dem Namensfeld wird bereits angezeigt, wie der Code für die Knoten-Parameter im Parameter-Feld und für die Knoten-Deklarationen im Text der Produktion für diesen Namen aussehen werden.
Auf der nächsten Seite des Assistenten belassen sie die Voreinstellung:

Wählen sie dann die Komplett-Option auf der nächsten Assistenten-Seite:
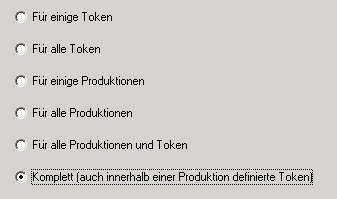
Auf der nächsten Seite des Assistenten stehen drei Optionen zur Behandlung der literalen Token zur Auswahl.

Für das Kopierprogramm muss der unterste Punkt gewählt werden.Dann wird nach jedem Vorkommen eines literalen Tokens im Projekt die semantische Aktion IgLit eingefügt, die dafür sorgt, dass dem Baum sowohl ein Knoten für die ausgelassenen Zeichen als auch ein Knoten für den erkannten Text hinzugefügt wird.
Die IgLit Funktion wird dann vom Assistenten auf der Element-Seite eingefügt. Sie sieht folgendermaßen aus:
Name: IgLit // Ignorierter Text und Literal
Parameter: node& xnNode, const str& xs
Text:
{{
node n("IgLit");
xnNode.addChildLast(n);
n.add("IGNORED", xState.str(-1));
n.add(xs, xState.str());
}}
Dem Baum-Knoten xnNode wird hier ein Unterknoten mit dem Label "Iglit" hinzugefügt, und dieser Unterknoten erhält die Knoten für den ausgelassenen Text und den vom Token erkannten Text.
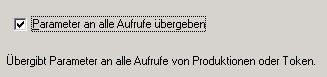
Auf der nächsten Seite aktivieren sie bitte die Box: Parameter an alle Aufrufe übergeben.
Dann können sie zur letzten Seite gehen und den Fertigstellen-Schalter anklicken.

Nachdem die Ergebnisse angezeigt wurden kann der Baum-Assistent mit dem Abbruch-Schalter geschlossen werden.
Der Baum, der nach Ausführung der Startregel CompilationUnit erzeugt wird kann im Variablen-Inspektor betrachtet werden, wie im XML-Beispiel beschrieben.
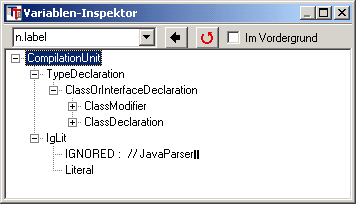
Anmerkung: An das Ende der Startregel CompilationUnit ist explizit das EOF-Symbol gesetzt. Für dieses Symbol ist vom Assistenten auch eine Aktion eingefügt worden:
EOF {{IgLit(n, "Literal");}}
In dieser letzten Aktion wird auch der auszulassende Text der dem letzten Token der Java-Grammatik nachfolgt, in den Baum eingefügt:
der Kommentar "// JavaParser"