Bedienung > Debuggen und Ausführen > Syntaxbaum > Anfängermenge zeigen
Über das Popup-Menü, das zu einem Knoten erscheint, wenn die rechte Maustaste gedrückt wurde, kann man sich Informationen über die Anfängermengen des Knotens anzeigen lassen, vorausgesetzt, er ist geparst.
Die Anzeige sieht beispielsweise folgendermaßen aus:
Anmerkung:
Zusätzlich wird ab der Version 0.9.8.8 eine Zeile mit den für den Knoten gültigen Optionen angezeigt, z.B.: Options: sep !icase, global ig lit (!all) !rgx. Die Bedeutung dieser Abkürzungen wird unten erklärt.
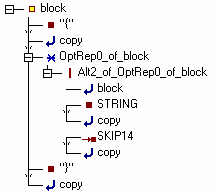
Diese Box gehört zum Knoten für die Alternative in der block-Produktion des guard-Beispiels:
block =
"{" copy_text
(
block
| STRING copy_text
| SKIP copy_text
)*
"}" copy_text
In der Baumansicht:
1. Titel
Im Titel der angezeigten Box steht der Name des Knotens.
2. Kopfzeile
In der ersten Zeile des Fensters steht, ob der Knoten löschbar ist oder nicht.
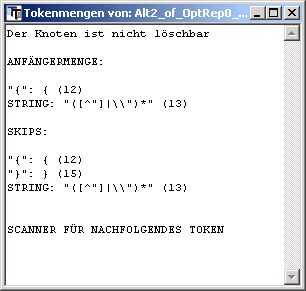
3. ANFÄNGERMENGE:
Mit "Anfängerliste" ist eine Liste überschrieben, deren Zeilen jeweils aus dem Namen, dem Text und der (automatisch vergebenen) Nummer von Token bestehen.
"{": { (12)
STRING: "([^"]|\\")*" (13)
Diese Liste enthält die eigentliche Anfängermenge des Knotens, d.h. alle Token, mit denen die alternativen Ketten, die in dem Knoten ihren Ursprung haben beginnen.
Im Beispiel handelt es sich um den Knoten, der die folgende Alternative darstellt:
block
| STRING copy_text
| SKIP copy_text
"{" ist das einzige Token mit dem die block-Produktion beginnen kann und
STRING ist ein alternatives Terminalsymbol.
4. SKIPS:
Falls zu den Alternativen des Knotens ein SKIP-Symbol gehört oder falls der Knoten selbst für ein SKIP-Symbol steht, wird dessen Tokenmenge hier angezeigt.
Im Beispiel:
"{": { (12)
"}": } (15)
STRING: "([^"]|\\")*" (13)
Im Quelltext wird nach der nächsten Position gesucht, an der eines dieser Token vorkommt, wenn an der aktuellen Textposition keines der unter 3. genannten Token gefunden wird.
5. SCANNER FÜR NACHFOLGENDES TOKEN
Nur, wenn es sich bei dem Knoten, dessen Informationen angezeigt werden, um ein Terminalsymbol oder um den Aufruf eines Nonterminals handelt, folgen weitere Tokenlisten für den "Scanner für nachfolgendes Token". Während in den Listen unter Punkt 3 und 4 die Token angeführt wurden, deren Erkennung zum Knoten führt, werden in den nachfolgenden Listen die Token angeführt, die zum nächsten Knoten leiten.
In der gleichen block-Produktion des obigen Beispiels sieht die Anzeige für den block-Knoten folgendermaßen aus:
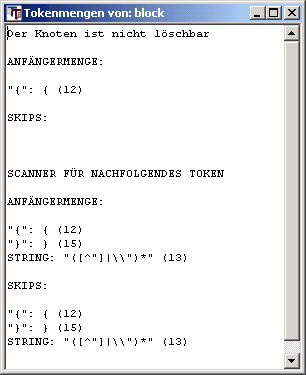
Nach dem rekursiven Aufruf der block-Produktion innerhalb ihrer selbst, muss nach dem nächsten Token im Text gesucht werden. Die Kandidaten der Suche sind in den Listen des Scanners für die nachfolgenden Token genannt. Entweder beginnt mit "{" sofort ein neuer Block oder es folgt ein String oder der aktuelle Block wird mit "}" verlassen. Trifft keiner der drei Fälle an der aktuellen Textposition zu, wird - wegen des SKIP-Symbols - im Text die nächste Stelle gesucht, an der einer der Fälle zutrifft.
6. NACHFOLGER IN ALLEN AUFRUFENDEN PRODUKTIONEN
Schließlich gibt es noch eine weitere Liste, falls der zugehörige Knoten zu einem Terminalsymbol gehört, das "am Ende" einer Produktion steht. "Am Ende" heißt, dass es zu dem Terminalsymbol ein nachfolgendes Token gibt, das sich nicht mehr in der gleichen Produktion befindet. In der block-Produktion trifft dies auf den Knoten für die schließende Klammer "}" zu. Die Anfängermengen für diesen Knoten sehen wie folgt aus:
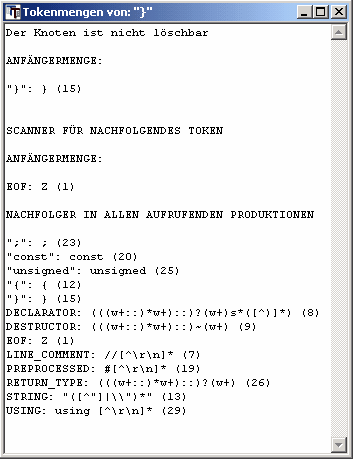
In der Liste der "NACHFOLGER IN ALLEN AUFRUFENDEN PRODUKTIONEN" befinden sich alle Token, die auf die Aufrufe der block-Produktion folgen können. Einen solchen Aufruf gibt es in der block-Produktion selbst. Deshalb müssen in der Liste aller token, die auf "}" folgen können auch alle die Token vorkommen, die auf diesen Aufruf folgen können. Diese Token wurden bereits unter Punkt 5 (SCANNER FÜR NACHFOLGENDES TOKEN) betrachtet:
"{": { (12)
"}": } (15)
STRING: "([^"]|\\")*" (13)
Die restlichen "NACHFOLGER IN ALLEN AUFRUFENDEN PRODUKTIONEN" folgen auf Aufrufe der block-Produktion innerhalb anderer Regeln.
Die letzte Liste sieht anders aus, wenn sie während des Debuggens des guard-Projekts angezeigt wird. Sie wird deshalb umbenannt in:
7. NACHFOLGER IN DEN AKTUELL AUFRUFENDEN PRODUKTIONEN
Jetzt werden nur noch diejenigen Token aufgelistet die tatsächlich im Moment folgen können, d.h. die Nachfolger des aktuellen Aufrufs der Produktion. Im Beispiel ist die aufrufende block-Produktion hier wiederum die block-Produktion selbst.:
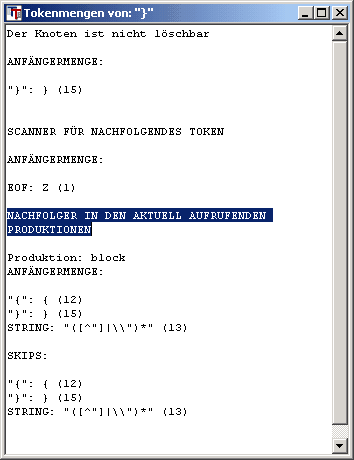
Jetzt werden nur noch die unter Punkt 5 besprochenen Token angezeigt. Token die auf andere Aufrufe der block-Produktion folgen können sind aktuell irrelevant.
Optionen:
Zusätzlich wird ab der Version 0.9.8.8 eine Zeile mit den für den Knoten gültigen Optionen angezeigt.
Zeichen |
Abkürzung für |
Bedeutung |
! |
|
nicht |
sep |
separated |
|
icase |
ignore case |
Gross-/kleinschreinbung nicht beachten |
global |
|
globale Scanner-Einstellung |
ig |
ignore |
auszulassende Zeichen |
lit |
literals |
literale Token |
all |
|
alle testen |
rgx |
regular expression |
nicht literale Token |
Z.B.:
Options: sep !icase, global ig lit (!all) !rgx
bedeutet, dass literale Token abgetrennte Worte sein müssen, dass Gross-/Kleinschreibung beachtet wird und dass die globalen Scanner für die auszulassenden Zeichen und für die literalen Token verwendet wird.