Bedienung > Hauptmenü > Menü: Hilfe > Regex Test
Unter dem Menüeintrag Hilfe gibt es den Unterpunkt Regex Test. Hier lässt sich ein Dialog aufrufen, in dem reguläre Ausdrücke einzeln getestet werden können. Die Ausdrücke sind hier in der gleichen Syntax anzugeben, wie auf der Tokenseite. D.h. vor den Metazeichen regulärer Ausdrücke muss ein Backslash '\' gesetzt werden, wenn das Zeichen in literaler Bedeutung interpretiert werden soll.
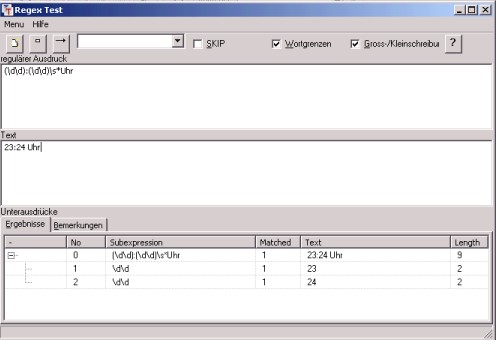
Die Dialogbox besteht aus einem Menü, einer Werkzeugleiste und drei Unterfenstern.
Die Menüpunkte sind auch direkt über die Schalter der Werkzeugleiste ausführbar:
Edit-felder löschen
Die Texte in den drei Unterfenstern der Dialogbox werden gelöscht.
Kompilieren
Der reguläre Ausdruck im obersten Fenster wird kompiliert. Je nachdem, ob die Syntax des Ausdrucks korrekt ist oder nicht wird der Erfolg bestätigt, oder das Auftreten eines Fehlers angezeigt.
Ausführen
Der reguläre Ausdruck im obersten Fenster wird kompiliert und auf den Text im mittleren Fenster angewandt. War der reguläre Ausdruck syntaktisch korrekt, wird er samt seinen Unterausdrücken im untersten Fenster aufgelistet. Rechts neben den jeweiligen Unterausdrücken wird angegeben, welcher Teil des Textes durch ihn erkannt wurde. (Im abgebildeten Beispiel enthält der 1. Unterausdruck die Stunden- und der zweite die Minutenzahl der Uhrzeit. Ein weiteres Beispiel wird im Waechterprojekt gezeigt.)
Auswahlbox
In der Auswahlbox der Werkzeugleiste sind alle Token des aktuellen Projekts aufgelistet. Bei der Wahl eines dieser Token, wird sein Definitionstext in das oberste Fenster übernommen.
Optionen
SKIP
Die Option SKIP ist normalerweise deaktiviert. Eine Übereinstimmung mit dem Text wird dann nur gefunden, wenn sie am Textanfang liegt, so wie beim beim Parsen eines Textes das nächste Token zumeist auf die aktuelle Textposition passen soll.
Ist die Option SKIP eingeschaltet, so wird nach der nächsten Stelle im gesamten Texte gesucht, auf die der reguläre Ausdruck passt. Wird eine Übereinstimmung am Textanfang gefunden, wird dies als Fehler gewertet.
Wortgrenzen
Die Wortgrenzen-Option hier wirkt sich für Literale auf die gleiche Weise aus, wie die Wortgrenzen-Option in den Projekteinstellungen. Die Auswertung geschieht hier wie bei den von TETRA erzeugten Parsern durch einen speziellen ternären Baum. Bei regulären Ausdrücken hat diese Option hier keine Auswirkungen, da der Ausdruck fertig aus dem obersten Editfeld übernommen wird.
Die SKIP-Ausdrücke einer Produktion werden hingegen erst beim Kompilieren des Projekts erzeugt und können somit literale Unterausdrücke mit Wortgrenzen enthalten. Wortgrenzen werden dann durch Einfügung der Anker "\<" und "\>" formuliert.
Gross-/Kleinschreibung
Die Gross-/Kleinschreibung-Option hier wirkt sich auf die gleiche Weise aus, wie die Gross-/Kleinschreibung-Option in den Projekteinstellungen.
Anmerkung:
Der Test der regulären Ausdrücke arbeitet in gleicher Weise, wie die Scanner in einem TextTransformer Projekt. Ist der Ausdruck im obersten Fenster ein Literal, so wird dies im Ergebnisfenster angegeben. Der Ausdruck wird dann auch nicht als regulärer Ausdruck, sondern eben als Literal getestet. Während '"' und '\"' für den regulären Ausdruck ununterschieden sind, gilt dies nicht für Literale.